-
AI and Lies: Replacing expertise with expectations
I went searching for an answer on the Internet; humans told me the truth, but the site wanted me to listen to an AI — and that AI lied to me.

Image generated on dream.ai This post is one of (what I hope will be) a series on the limitations and negative consequences of artificial intelligence systems on language. My particular research focus is on the willingness of AI/LLM systems like ChatGPT to lie confidently instead of admitting uncertainty, and some of the dangers that this presents as these tools are quickly, perhaps unthinkingly, adopted.
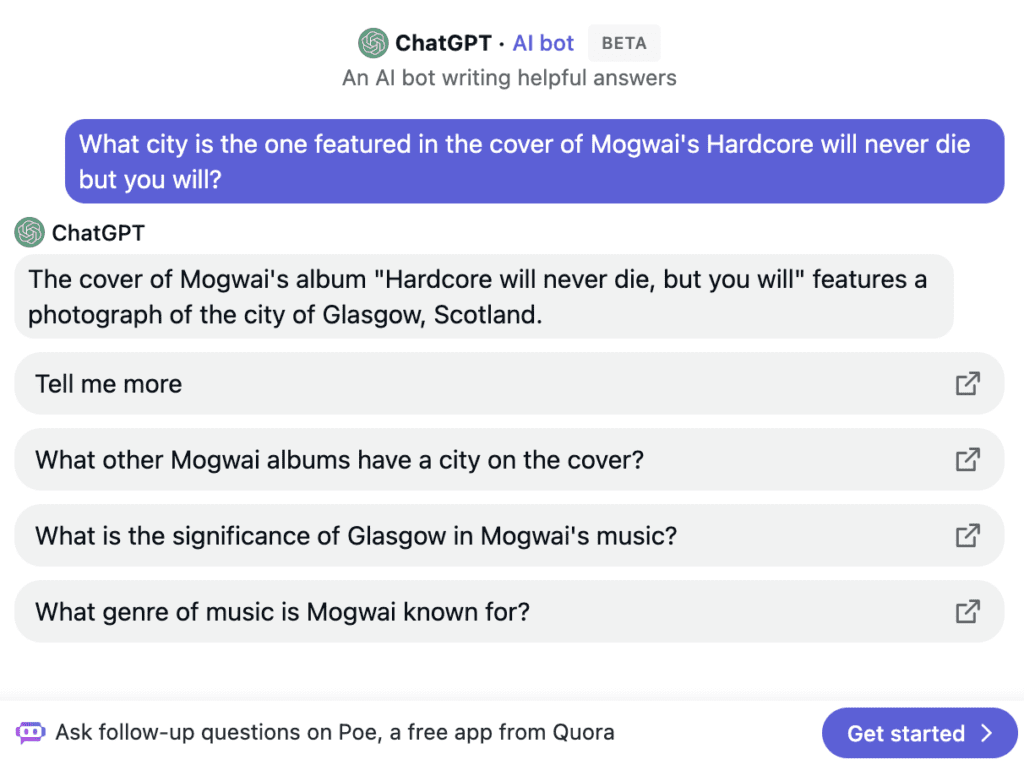
Today, I’m focused on Quora’s experiment replacing human-powered answers with LLM-based answers, and the curious choice to put the auto-generated wrong answer above the correct answers on their website.
Human and computer knowledge bases are an ocean apart
I’m a big fan of the band Mogwai, and do a lot of writing while listening to their albums. The other day, I was listening to their 2011 album, Hardcore Will Never Die, But You Will, and looking at the cover photo. The album cover is a picture of some city at dusk, and I was curious where it was, especially as it seemed just a little familiar. I also was open to a rewarding distraction, as the task I was working on was pretty dull.
So I did a quick Google search and got a hit from Quora, a crowd-sourced question answering forum. Someone had asked exactly my question: What city is the one featured in the cover of Mogwai’s Hardcore will never die but you will?, and two people had answered, both saying it was New York City. One had even included a link to a Google Street View from the George Washington Bridge, replicating the view from the album cover. Perfect answers, provided by helpful humans, shortly after the album was released, and encased in Internet amber for me to learn from 11 years later. Better yet, my seeming familiarity was not totally wrong; I had visited my cousin when he was living in this part of New York a few years ago!
But this is not a story about learning an inconsequential fact. It is a story about AI, and specifically about the bad implementation of an large language model. I mentioned the two excellent human answers to this question on Quora’s site, but I didn’t mention that to get to them, I had to scroll past an AI-generated response, based on ChatGPT. (Just in case Quora has changed their website since I’ve written this, here’s an archived link so you can see the page with the AI-generated answer.)
And why did I have to scroll past it? Not out of a camadarie to my fellow humans, but because it was straight-up wrong. The bot said said that the cover art was a picture of Glasgow, Scotland. It’d be a reasonable guess at a bar trivia night or something, as Mogwai are Glaswegian, but anybody who plays an unreasonable amount of Geoguessr would be immediately suspicious that the city looked more American than Scottish.
When I clicked on the chatbot’s answer, the above conversation greeted me. It matter-of-factly states a completely incorrect answer. Worse, you’ll note that everything on this screen is intended to convince the viewer that the chatbot is correct and trustworthy, or at least to avoid giving you any reason to distrust its answer.
“An AI bot writing helpful answers” is probably the most galling part to me. The helpful answers were those from the real humans, better answers than I could have hoped for. The AI’s simulacrum of those answers is a guess based on the fact that the band itself is from Glasgow. And Quora put this above the actually correct human answers!
But also notice the straightforward, factual tone of the answer, and the “Tell me more” carrying a presupposition that the previous information was correct enough to follow up on. The user interface subtly encourages the user to leave their skepticism behind.
Tell me more… okay, no, stop.
Well, I followed the first suggestion and asked the bot to tell me more. It said it would only do so if I logged into its system. Fine. I logged in and it told me more! And it lied to me again:
Sure! Mogwai is a Scottish post-rock band that formed in Glasgow in 1995, and the city has played an important role in the band’s history and music. The cover of their 2011 album “Hardcore will never die, but you will” features a photograph of the iconic motorway junction at Charing Cross in Glasgow, which is a busy intersection of several major roads.
That first sentence is true enough, though irrelevant. In fact, this album included a song titled George Square Thatcher Death Party, in reference to a major square in Glasgow (and when Margaret Thatcher died two years after the album’s release, an impromptu party celebrating her death did happen in that square!). But the second is, to borrow a what I think is a Scottish phrase, talking mince — rubbish.
Charing Cross is a major motorway junction in Glasgow, but it’s not pictured on the album cover. The bot has called up a correct piece of information but applied it incorrectly. Worse, it’s not obvious that it’s wrong; there is no signal to the reader to doubt this; there’s enough of a highway in the cover picture that you could easily imagine that that’s the “iconic motorway junction” that the bot mentions. Figuring out if the bot is lying is not super difficult, but it’s more effort than you’d go to unless you had a good reason to distrust the bot.
It took me a minute or two to look up Charing Cross on Google Maps, get into street view, and look around enough to make sure that the album image couldn’t match the intersection. It’s always hard to prove a negative, so even now I can’t 100% say that the image can’t be of Glasgow, but here are Google Street Views of Charing Cross in Glasgow on the left (the AI’s answer) and of Washington Heights in New York on the right (the humans’ answer). I’m convinced the AI is wrong, but only because some kind souls provided enough information for me to find a convincing alternative explanation.
Charing Cross in Glasgow Washington Heights in NYC Building and breaking trust in AI
Wrong answers in such question-answering settings are particularly dangerous, since the very fact that a user is asking a question implies that they don’t know the correct answer and have a limited capacity to distinguish good and bad answers. Let me walk you through why I think the auto-suggested “tell me more” answer is particularly dangerous for discouraging skepticism.
I was asking a fairly specific question within a topic, suggesting that I knew the basics of the topic and wanted info on a more advanced aspect at the edge of my knowledge. The bot responded by first providing me with an accurate summary of the basics of the topic, information that I had a solid knowledge base about. (In terms of conversational pragmatics, I’ve signalled that baseline knowledge of Mogwai is in our conversational common ground by stating the existence of the band and this album as given information, and then asking my question based off of this information.) The bot is building my sense of trust and reliability in it with that first sentence, rather than conveying requested, novel information. I can almost hear the unstated “As you already know…” at the beginning of its response.
But then it subverts this trust; when the response turns to the limits of my knowledge, the bot gives no indication that this information is any less certain than the previous sentence’s. It grounds its answer with additional truthful, easily verifiable details (the fact that there is a major junction at Charing Cross, which shows up on Wikipedia), while just making up the critical, hard-to-verify and unknown-to-me information that the image is of Charing Cross. On every aspect that I can easily check the bot’s veracity, it passes; only at the point where my knowledge wanes and I have to trust it does it betray me. It’s a classic con-man move, but it’s almost more frustrating than being actively conned. At least a con-man benefits by getting my money. The bot doesn’t get any joy from tricking me into believing a lie; it just makes me dumber.
That’s a big danger with these systems; by mimicking a knowledgable human’s style — building trust and then paying it off — but lacking that critical bit of being knowledgable, these bots become pathological liars. And because it is so much easier to be told a lie than to track down the truth, the trust built up by the accurate preface means that this (unintentional) lie is likely to go undetected.
Output becomes input
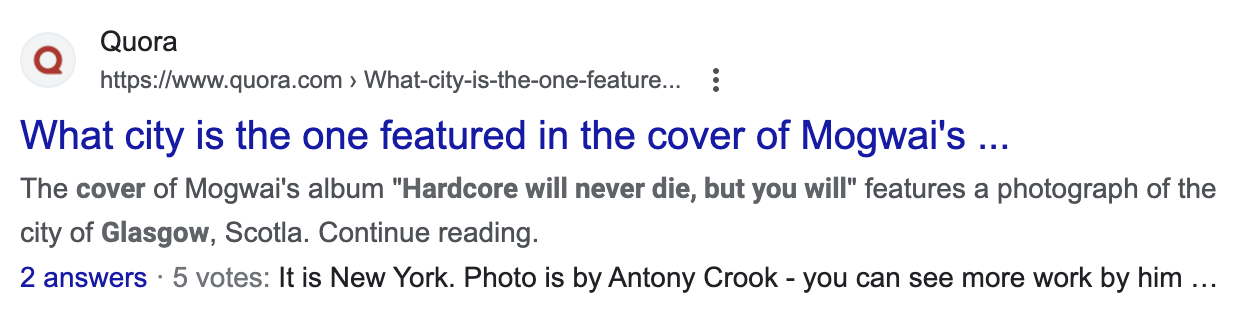
Now, this wouldn’t be a big problem if it were only lying to me. I’m not a great conversationalist, but even I’d have to be digging pretty deep into my small-talk options before I brought up this album cover’s location in a conversation. But this lie now appears at the top of the page for Quora, a pretty major web portal. And as a result, Google has extracted the bot’s answer, rather than the humans’, as the snippet for the the Google search on this page:
Human searchers might just skim through this miss the follow-up: “It is New York”. Worse, from here, it’s a small step away from getting internalized into Google’s knowledge base and shown as a fact in one of the search engine’s infoboxes (or knowledge panels, as it calls them). Information that makes into these panels are often disconnected from their sources, barely cited at best, and lead to various mistaken conclusions. If our bot-friend’s unsourced claim makes that jump, both humans and other AIs will start learning it over the more correct but less prominent truth.
This is one of my greatest fears of the unintended consequence of large language model (LLM) beta periods. Yes, you can argue that a user ought to know better than to trust these systems, but when the system is so matter-of-fact, and the only signal not to trust it is a little “BETA” tag at the top, you’re sending the message that they can trust them. So now a fake fact has entered into the discourse. It might even get scooped up into the next round of training data for the next LLM. And LLMs, like ChatGPT, are perhaps the most credulous consumers of information, as they have no way of assessing reality. As long as it makes it into the training data, it’s learning from it.
So what do we do?
I don’t know what we should do about this; or rather, I fear that the only reasonable answer is, essentially, to shut it all down or heavily regulate it. At the very least, we need to revise our LLMs to express uncertainty. We’ve ended up with systems that value stating things confidently over expressing uncertainty; systems that would rather lie to you than admit they don’t know enough. And that’s because they’ve been trained to talk like us, without knowing what we know. The training data for LLMs focuses on confident statements of fact, because they’re made by (mostly) knowledgeable humans. The LLMs ape our style, but not our understanding, because the scoring functions used to train the models says that that’s what humans like. We like certainty! But it misses the point that we only really like certainty when it’s earned.
By creating plausible lies and failing to express uncertainty or any useful caveats, LLMs are constantly generating and opening Pandora’s boxes. Fact-checking is always going to be a slow process compared to “fact”-creating, and as LLM-generated data breaks containment, it’s going to undermine our trust in any information we see. LLMs and chatbots are really cool, and they might even end up giving us useful insights into human language. But their consequences are essentially unfathomable at this point, and I increasingly worry that the lasting harms from their unregulated roll-out are more substantial and less recoverable than we think.

Associate Professor; Thinking about thinking about language